Năm 2000
(Nội dung chủ yếu được dịch từ trang Web https://www.nobelprize.org )
Giải Nobel Kinh tế 2000
Giải Sveriges Riksbank về Khoa học Kinh tế tưởng nhớ Alfred Nobel năm 2000 được trao đồng đều cho James J. Heckman
“vì đã phát triển lý thuyết và phương pháp phân tích các mẫu chọn lọc (selective samples)”
“for his development of theory and methods for analyzing selective samples”
và Daniel L. McFadden
“vì đã phát triển lý thuyết và phương pháp phân tích lựa chọn rời rạc”.
“for his development of theory and methods for analyzing discrete choice”
Người đoạt giải
James J. Heckman

James J. Heckman sinh ngày 19 tháng 4 năm 1944 tại Chicago, bang Illinois, Hoa Kỳ. James Heckman theo học đại học tại Colorado Springs, bang Colorado, nơi ông chọn toán học làm chuyên ngành. Sau đó, ông tiếp tục nghiên cứu kinh tế học tại Đại học Princeton và nhận bằng Tiến sĩ năm 1971. Trong sự nghiệp học thuật của mình, ông đã giảng dạy tại nhiều cơ sở đào tạo trước khi gia nhập Khoa Kinh tế của Đại học Chicago, nơi ông gắn bó lâu dài và tạo dựng ảnh hưởng học thuật sâu rộng.
Daniel L. McFadden

Daniel L. McFadden sinh ngày 29 tháng 7 năm 1937 tại Raleigh, bang North Carolina, Hoa Kỳ. Daniel McFadden lớn lên tại một trang trại nông thôn, nơi cộng đồng dân cư thưa thớt và đọc sách là hình thức giải trí chủ yếu. Ông theo học vật lý và kinh tế học tại Đại học Minnesota, qua đó hình thành nền tảng vững chắc về tư duy phân tích và định lượng. Trong sự nghiệp giảng dạy và nghiên cứu, ông từng công tác tại nhiều cơ sở đào tạo danh tiếng như Đại học California, Berkeley, Đại học Yale và Viện Công nghệ Massachusetts (MIT); đến năm 1990, ông trở lại giảng dạy tại Berkeley. Tại thời điểm được trao giải Nobel Kinh tế, ông là giáo sư tại Đại học California, Berkeley.
Công trình của Daniel L. McFadden kết hợp chặt chẽ lý thuyết kinh tế, phương pháp thống kê và ứng dụng thực nghiệm nhằm giải quyết các vấn đề xã hội cụ thể. Trong thập niên 1970, ông đã phát triển phương pháp logit có điều kiện (conditional logit analysis) – một công cụ then chốt để phân tích cách các cá nhân lựa chọn giữa một tập hữu hạn các phương án nhằm tối đa hóa lợi ích. Phương pháp này đã được ứng dụng rộng rãi, chẳng hạn trong việc dự báo mức độ sử dụng các hệ thống giao thông công cộng, cũng như trong nhiều lĩnh vực khác như môi trường, y tế và chính sách công.
Nội dung nghiên cứu của giải Nobel Kinh tế 2000
Kinh tế lượng vi mô (microeconometrics) là lĩnh vực giao thoa giữa kinh tế học và thống kê học. Lĩnh vực này bao gồm các lý thuyết kinh tế và phương pháp thống kê được sử dụng để phân tích dữ liệu vi mô, tức là các thông tin kinh tế về cá nhân, hộ gia đình và doanh nghiệp. Dữ liệu vi mô có thể xuất hiện dưới dạng dữ liệu chéo (cross-section), phản ánh các điều kiện tại cùng một thời điểm, hoặc dưới dạng dữ liệu dọc/chuỗi theo thời gian cho cùng đối tượng quan sát (longitudinal data hay panel data), phản ánh cùng một đơn vị quan sát qua nhiều năm liên tiếp. Trong ba thập niên gần đây, lĩnh vực kinh tế lượng vi mô đã phát triển rất nhanh, chủ yếu nhờ sự hình thành của các cơ sở dữ liệu lớn chứa dữ liệu vi mô.
Việc gia tăng khả năng tiếp cận dữ liệu vi mô cùng với sự phát triển của máy tính ngày càng mạnh đã mở ra những khả năng hoàn toàn mới trong việc kiểm định thực nghiệm các lý thuyết kinh tế vi mô. Các nhà nghiên cứu có thể phân tích nhiều vấn đề mới ở cấp độ cá nhân. Chẳng hạn: những yếu tố nào quyết định việc một cá nhân tham gia lao động hay không, và nếu có thì làm việc bao nhiêu giờ? Các động cơ kinh tế ảnh hưởng như thế nào đến các lựa chọn cá nhân về giáo dục, nghề nghiệp hay nơi cư trú? Các chương trình thị trường lao động và chương trình giáo dục khác nhau tác động ra sao đến thu nhập và việc làm của từng cá nhân?
Tuy nhiên, việc sử dụng dữ liệu vi mô cũng làm nảy sinh những vấn đề thống kê mới, chủ yếu do các hạn chế vốn có của loại dữ liệu này (dữ liệu không thực nghiệm - non-experimental). Do nhà nghiên cứu chỉ có thể quan sát một số biến nhất định đối với từng cá nhân hay hộ gia đình cụ thể, nên mẫu dữ liệu có thể không ngẫu nhiên, và vì thế không mang tính đại diện. Ngay cả khi mẫu là đại diện, vẫn tồn tại những đặc điểm không quan sát được ảnh hưởng đến hành vi của cá nhân, khiến cho việc giải thích – thậm chí là không thể giải thích – một phần sự khác biệt giữa các cá nhân trở nên rất khó khăn.
Các nhà khoa học đoạt giải năm nay mỗi người theo cách riêng đã chỉ ra cách giải quyết một số vấn đề thống kê cơ bản gắn liền với việc phân tích dữ liệu vi mô. Những đóng góp phương pháp luận của James Heckman và Daniel McFadden đều có nền tảng vững chắc trong lý thuyết kinh tế. Các phương pháp này hình thành thông qua sự tương tác chặt chẽ với các nghiên cứu thực nghiệm ứng dụng, trong đó các cơ sở dữ liệu mới đóng vai trò là điều kiện tiên quyết. Ngày nay, các phương pháp kinh tế lượng vi mô do Heckman và McFadden phát triển đã trở thành bộ công cụ tiêu chuẩn, không chỉ của các nhà kinh tế học mà còn của nhiều nhà khoa học xã hội khác.
James J. Heckman
James Heckman đã có nhiều đóng góp quan trọng cho lý thuyết và phương pháp luận của kinh tế lượng vi mô, trong đó các vấn đề chọn mẫu (selection problems) là điểm chung xuyên suốt. Ông phát triển các đóng góp phương pháp này gắn liền với nghiên cứu thực nghiệm ứng dụng, đặc biệt trong kinh tế học lao động. Phân tích của Heckman về các vấn đề chọn mẫu trong nghiên cứu kinh tế lượng vi mô đã tạo ra những hàm ý sâu sắc đối với nghiên cứu ứng dụng trong kinh tế học cũng như nhiều ngành khoa học xã hội khác.
Sai lệch chọn mẫu và vấn đề tự lựa chọn - Selection Bias and Self-selection
Các vấn đề chọn mẫu xuất hiện rất phổ biến trong các nghiên cứu kinh tế lượng vi mô. Chúng phát sinh khi mẫu dữ liệu mà nhà nghiên cứu quan sát được không đại diện ngẫu nhiên cho tổng thể cơ bản. Các mẫu chọn lọc có thể là kết quả của quy tắc thu thập dữ liệu, hoặc là hệ quả từ hành vi của chính các tác nhân kinh tế. Trường hợp thứ hai được gọi là tự chọn (self-selection). Ví dụ, tiền lương và số giờ làm việc chỉ có thể quan sát được đối với những cá nhân đã lựa chọn đi làm; thu nhập của người tốt nghiệp đại học chỉ có thể quan sát đối với những người đã hoàn thành bậc học đại học, v.v. Việc thiếu thông tin về mức lương mà một cá nhân có thể nhận được nếu họ lựa chọn khác đi tạo ra khó khăn trong nhiều nghiên cứu thực nghiệm.
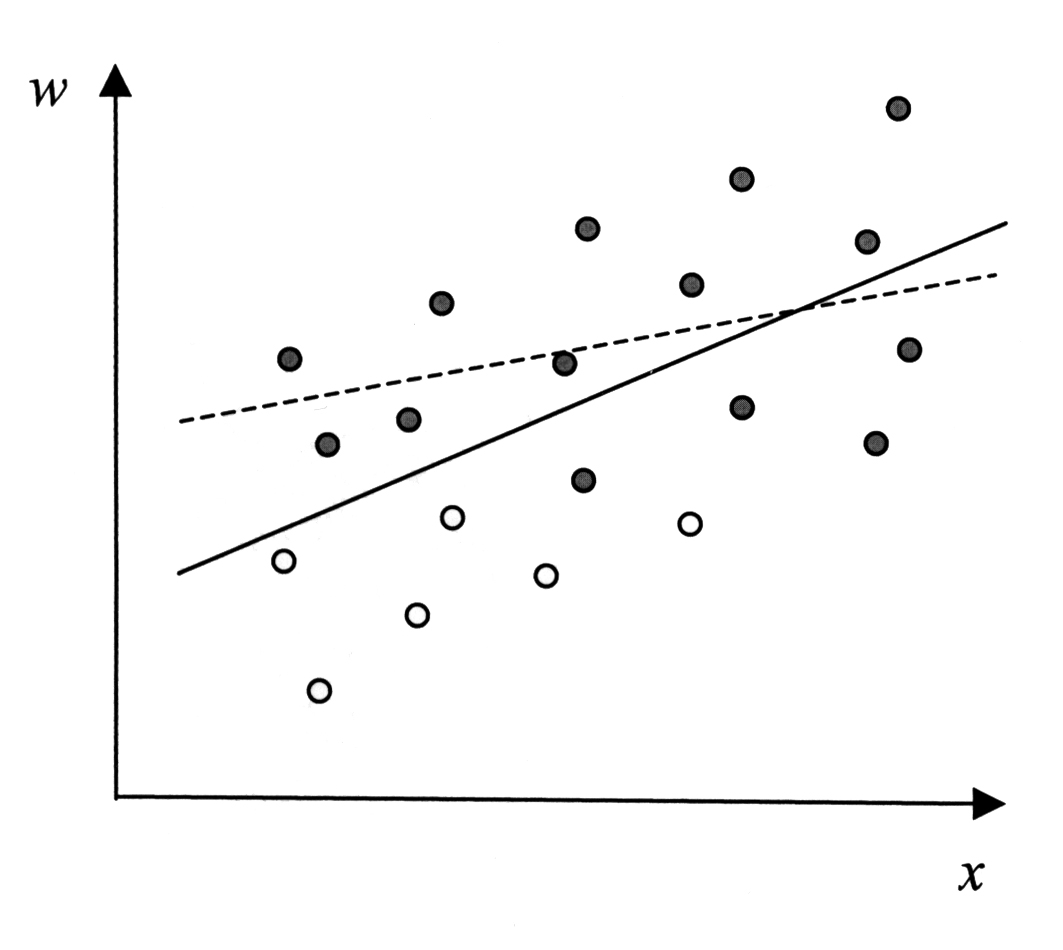
Vấn đề sai lệch chọn mẫu (selection bias) có thể được minh họa bằng hình sau, trong đó \(w\) ký hiệu tiền lương của một cá nhân và \(x\) là một yếu tố ảnh hưởng đến tiền lương đó, chẳng hạn như trình độ học vấn. Mỗi điểm trong hình đại diện cho các cá nhân có cùng mức học vấn và tiền lương trong một mẫu lớn và đại diện của dân số. Đường liền nét biểu thị mối quan hệ thống kê (và cũng là mối quan hệ thực) mà ta sẽ ước lượng nếu có thể quan sát tiền lương và học vấn của tất cả các cá nhân này.
Giờ giả sử – phù hợp với lý thuyết kinh tế – rằng chỉ những cá nhân có mức lương thị trường vượt quá một ngưỡng nhất định (gọi là mức lương dự trữ – reservation wage) mới quyết định tham gia lao động. Khi đó, những cá nhân có tiền lương tương đối cao và trình độ học vấn tương đối dài sẽ xuất hiện nhiều hơn trong mẫu mà ta thực sự quan sát được (các điểm đậm trong hình). Mẫu chọn lọc này tạo ra vấn đề sai lệch chọn mẫu, theo đó mối quan hệ giữa tiền lương và học vấn mà ta ước lượng sẽ là đường nét đứt trong hình.
Kết quả là, ta tìm thấy một mối quan hệ yếu hơn so với mối quan hệ thực, và do đó đánh giá thấp tác động của giáo dục đối với tiền lương.
Đóng góp của Heckman - Heckman’s Contributions
Những đột phá phương pháp luận của James Heckman liên quan đến tự chọn (self-selection) xuất hiện vào giữa thập niên 1970, gắn chặt với các nghiên cứu của ông về quyết định tham gia lực lượng lao động và số giờ làm việc của cá nhân. Do ta chỉ quan sát được sự khác biệt về số giờ làm việc ở những người đã lựa chọn đi làm, nên một lần nữa có thể gặp phải mẫu dữ liệu bị nhiễm tự chọn. Trong một bài báo về cung lao động của phụ nữ đã kết hôn công bố năm 1974, Heckman đã xây dựng một phương pháp kinh tế lượng để xử lý các vấn đề tự chọn như vậy. Nghiên cứu này là minh họa xuất sắc cho việc kết hợp lý thuyết kinh tế vi mô với phương pháp kinh tế lượng vi mô nhằm làm sáng tỏ một chủ đề nghiên cứu quan trọng.
Trong các công trình tiếp theo, Heckman đề xuất thêm một phương pháp khác để xử lý tự chọn: hiệu chỉnh Heckman nổi tiếng (còn gọi là phương pháp hai giai đoạn, lambda của Heckman hay Heckit). Phương pháp này có ảnh hưởng rất lớn vì dễ áp dụng. Giả sử một nhà nghiên cứu – như trong ví dụ nêu trên – muốn ước lượng mối quan hệ tiền lương bằng dữ liệu cá nhân, nhưng chỉ quan sát được tiền lương của những người đang đi làm. Hiệu chỉnh Heckman được thực hiện qua hai giai đoạn.
Giai đoạn thứ nhất, nhà nghiên cứu xây dựng một mô hình xác suất đi làm dựa trên lý thuyết kinh tế. Việc ước lượng thống kê mô hình này cho phép dự báo xác suất đi làm cho từng cá nhân.
Giai đoạn thứ hai, nhà nghiên cứu hiệu chỉnh tự chọn bằng cách đưa xác suất dự báo của từng cá nhân vào phương trình tiền lương như một biến giải thích bổ sung, cùng với các biến như trình độ học vấn, tuổi, v.v. Khi đó, mối quan hệ tiền lương có thể được ước lượng một cách phù hợp về mặt thống kê.
Những thành tựu của Heckman đã tạo ra rất nhiều ứng dụng thực nghiệm trong kinh tế học cũng như các ngành khoa học xã hội khác. Phương pháp ban đầu này sau đó tiếp tục được mở rộng và khái quát hóa, cả bởi chính Heckman và bởi nhiều nhà nghiên cứu khác.
Mô hình thời gian tồn tại - Duration Models
Các mô hình thời gian tồn tại có truyền thống lâu đời trong khoa học kỹ thuật và y học. Chúng cũng được các nhà khoa học xã hội, chẳng hạn như nhân khẩu học, sử dụng rộng rãi để nghiên cứu tử vong, sinh sản và di cư. Trong kinh tế học, các mô hình này được áp dụng, ví dụ, để phân tích tác động của thời gian thất nghiệp đối với xác suất tìm được việc làm.
Một vấn đề phổ biến trong các nghiên cứu như vậy là những cá nhân có triển vọng kém trên thị trường lao động có thể xuất hiện quá mức trong nhóm những người tiếp tục thất nghiệp. Kiểu sai lệch chọn mẫu này dẫn đến các vấn đề tương tự như trong các mẫu tự chọn: khi mẫu những người thất nghiệp tại một thời điểm nhất định bị chi phối bởi các đặc điểm cá nhân không quan sát được, ta có thể thu được những ước lượng sai lệch về cái gọi là “phụ thuộc vào thời gian” (duration dependence) của tình trạng thất nghiệp.
Trong hợp tác với Burton Singer, James Heckman đã phát triển các phương pháp kinh tế lượng nhằm giải quyết những vấn đề này. Ngày nay, phương pháp luận này được sử dụng rộng rãi trong toàn bộ các ngành khoa học xã hội.
Đánh giá các chương trình thị trường lao động chủ động - Evaluation of Active Labor Market Programs
Cùng với sự phổ biến của chính sách thị trường lao động chủ động – chẳng hạn như đào tạo nghề hoặc trợ cấp việc làm – tại nhiều quốc gia, nhu cầu đánh giá hiệu quả của các chương trình này ngày càng gia tăng. Cách tiếp cận kinh điển là xác định việc tham gia một chương trình cụ thể ảnh hưởng như thế nào đến thu nhập hoặc tình trạng việc làm của cá nhân, so với trường hợp cá nhân đó không tham gia. Tuy nhiên, vì không thể quan sát cùng một cá nhân trong hai trạng thái đồng thời, nên phải sử dụng thông tin về những người không tham gia, từ đó – một lần nữa – làm phát sinh các vấn đề chọn mẫu.
James Heckman là nhà nghiên cứu hàng đầu thế giới trong lĩnh vực đánh giá vi mô các chương trình thị trường lao động bằng kinh tế lượng. Hợp tác với nhiều đồng nghiệp, ông đã phân tích sâu rộng các đặc tính của những phương pháp đánh giá phi thực nghiệm khác nhau và khảo sát mối liên hệ của chúng với các phương pháp thực nghiệm. Heckman cũng đã đưa ra nhiều kết quả thực nghiệm của riêng mình.
Mặc dù kết quả khác nhau đáng kể giữa các chương trình và giữa các nhóm tham gia, nhưng kết luận thường khá bi quan: nhiều chương trình chỉ tạo ra tác động tích cực nhỏ – và trong một số trường hợp là tác động tiêu cực – đối với người tham gia, đồng thời không đáp ứng được tiêu chí hiệu quả xã hội.
Daniel L. McFadden
Đóng góp quan trọng nhất của Daniel L. McFadden là việc ông phát triển lý thuyết kinh tế và phương pháp kinh tế lượng để phân tích lựa chọn rời rạc (discrete choice), tức là việc lựa chọn giữa một tập hữu hạn các phương án quyết định. Một chủ đề xuyên suốt trong nghiên cứu của McFadden là khả năng kết hợp chặt chẽ giữa lý thuyết kinh tế, phương pháp thống kê và các ứng dụng thực nghiệm, trong đó mục tiêu cuối cùng của ông thường là giải quyết các vấn đề xã hội.
Phân tích lựa chọn rời rạc (Discrete Choice Analysis)
Dữ liệu vi mô thường phản ánh các lựa chọn rời rạc. Trong một cơ sở dữ liệu, thông tin về nghề nghiệp, nơi cư trú hay phương thức đi lại của cá nhân phản ánh những lựa chọn mà họ đã đưa ra trong một tập hợp hữu hạn các phương án. Trong lý thuyết kinh tế, phân tích cầu truyền thống giả định rằng lựa chọn cá nhân được biểu diễn bằng một biến liên tục, vì vậy không phù hợp để nghiên cứu hành vi lựa chọn rời rạc. Trước những đóng góp đoạt giải của McFadden, các nghiên cứu thực nghiệm về những lựa chọn như vậy thiếu nền tảng vững chắc trong lý thuyết kinh tế.
Đóng góp của McFadden
Lý thuyết lựa chọn rời rạc của McFadden xuất phát từ lý thuyết kinh tế vi mô, theo đó mỗi cá nhân lựa chọn một phương án cụ thể nhằm tối đa hóa lợi ích của mình. Tuy nhiên, do nhà nghiên cứu không thể quan sát tất cả các yếu tố ảnh hưởng đến lựa chọn của cá nhân, nên sẽ xuất hiện biến thiên ngẫu nhiên giữa các cá nhân có cùng những đặc điểm quan sát được. Dựa trên lý thuyết mới này, McFadden đã phát triển các mô hình kinh tế lượng vi mô có thể được sử dụng, chẳng hạn, để dự báo tỷ lệ dân số lựa chọn các phương án khác nhau.
Đóng góp mang tính khai phá của McFadden là việc ông phát triển phân tích logit có điều kiện (conditional logit analysis) vào năm 1974. Để mô tả mô hình này, giả sử rằng mỗi cá nhân trong một quần thể phải đối mặt với một số (giả sử là \(J\)) phương án lựa chọn. Ký hiệu \(X\) là các đặc trưng gắn với từng phương án, còn \(Z\) là các đặc trưng của cá nhân mà nhà nghiên cứu có thể quan sát trong dữ liệu. Chẳng hạn, trong một nghiên cứu về lựa chọn phương thức đi lại, nơi các phương án có thể là ô tô, xe buýt hoặc tàu điện ngầm, thì \(X\)sẽ bao gồm thông tin về thời gian và chi phí, trong khi \(Z\) có thể bao gồm dữ liệu về tuổi, thu nhập và trình độ học vấn.
Tuy nhiên, những khác biệt giữa các cá nhân và giữa các phương án ngoài \(X\) và \(Z\) — dù không quan sát được đối với nhà nghiên cứu — cũng ảnh hưởng đến lựa chọn tối đa hóa lợi ích của cá nhân. Những đặc điểm này được biểu diễn bằng các “thành phần sai số” ngẫu nhiên. McFadden giả định rằng các sai số ngẫu nhiên này tuân theo một phân phối thống kê cụ thể (gọi là phân phối giá trị cực trị – extreme value distribution) trong quần thể. Dưới những điều kiện này (cùng với một số giả định kỹ thuật), ông đã chứng minh rằng xác suất để cá nhân \(i\) lựa chọn phương án \(j\) có thể được viết dưới dạng:
\[ P_{ij} = \frac{\exp\left(X_{ij}\beta+Z_i\delta_j \right)} {\sum_{k=1}^{J} \exp\left( X_{ik}\beta+Z_i\delta_k \right)} \]
Trong mô hình được gọi là logit đa thức (multinomial logit) này, \(e\) là cơ số của logarit tự nhiên, còn \(\beta\) \(\delta\) là các tham số (dưới dạng vector). Trong cơ sở dữ liệu của mình, nhà nghiên cứu có thể quan sát các biến \(X\) và \(Z\), cũng như phương án mà cá nhân thực sự lựa chọn. Nhờ đó, ông có thể ước lượng các tham số \(\beta\) \(\delta\) bằng những phương pháp thống kê quen thuộc.
Mặc dù các mô hình logit đã tồn tại từ trước, nhưng cách dẫn xuất mô hình của McFadden là hoàn toàn mới và ngay lập tức được công nhận là một bước đột phá mang tính nền tảng.
Các mô hình như vậy rất hữu ích và được áp dụng thường xuyên trong các nghiên cứu về nhu cầu đi lại đô thị. Nhờ đó, chúng có thể được sử dụng trong quy hoạch giao thông để xem xét tác động của các biện pháp chính sách, cũng như của những thay đổi xã hội và/hoặc môi trường khác. Chẳng hạn, các mô hình này có thể giải thích cách sự thay đổi về giá, mức độ tiếp cận được cải thiện hoặc sự dịch chuyển trong cơ cấu nhân khẩu học của dân số ảnh hưởng đến tỷ lệ lựa chọn các phương thức giao thông khác nhau.
Các mô hình này cũng có ý nghĩa trong nhiều lĩnh vực khác, như nghiên cứu về lựa chọn nhà ở, nơi cư trú và giáo dục. McFadden đã áp dụng chính các phương pháp của mình để phân tích nhiều vấn đề xã hội, chẳng hạn như nhu cầu sử dụng năng lượng trong khu dân cư, dịch vụ điện thoại và nhà ở cho người cao tuổi.
Hoàn thiện phương pháp luận
Các mô hình logit có điều kiện (conditional logit) có một đặc tính đặc biệt: xác suất tương đối của việc lựa chọn giữa hai phương án, chẳng hạn như đi xe buýt hay ô tô, không phụ thuộc vào giá cả và chất lượng của các phương thức vận chuyển khác. Thuộc tính này – được gọi là tính độc lập của các phương án không liên quan (Independence of Irrelevant Alternatives – IIA) – là không thực tế trong một số ứng dụng. McFadden không chỉ xây dựng các kiểm định thống kê để xác định liệu giả định IIA có được thỏa mãn hay không, mà còn giới thiệu những mô hình tổng quát hơn, chẳng hạn như mô hình logit lồng ghép (nested logit). Trong mô hình này, người ta giả định rằng các lựa chọn của cá nhân có thể được sắp xếp theo một trình tự nhất định. Ví dụ, khi nghiên cứu các quyết định liên quan đến nơi cư trú và loại hình nhà ở, cá nhân được giả định là trước hết lựa chọn địa điểm, sau đó mới lựa chọn loại nhà.
Ngay cả với những mở rộng này, các mô hình vẫn nhạy cảm với những giả định cụ thể về phân phối của các đặc điểm không quan sát được trong dân số. Trong thập niên gần đây, McFadden đã tiếp tục phát triển các mô hình mô phỏng (đặc biệt là phương pháp mô men mô phỏng – method of simulated moments) để ước lượng thống kê các mô hình lựa chọn rời rạc với những giả định tổng quát hơn nhiều. Sự phát triển của máy tính ngày càng mạnh đã làm tăng đáng kể tính khả thi trong thực tiễn của các phương pháp số này. Nhờ đó, các lựa chọn rời rạc của cá nhân ngày nay có thể được mô tả một cách thực tế hơn và dự báo chính xác hơn.
Những đóng góp khác
Bên cạnh phân tích lựa chọn rời rạc, Daniel L. McFadden còn có nhiều đóng góp có ảnh hưởng trong một số lĩnh vực khác. Trong thập niên 1960, ông đã phát triển các phương pháp kinh tế lượng để đánh giá công nghệ sản xuất và phân tích những yếu tố chi phối nhu cầu về vốn và lao động của doanh nghiệp. Sang thập niên 1990, McFadden đóng góp quan trọng cho kinh tế học môi trường, đặc biệt là các nghiên cứu về phương pháp định giá ngẫu nhiên (contingent valuation) nhằm ước lượng giá trị của các tài nguyên thiên nhiên.
Một ví dụ tiêu biểu là nghiên cứu của ông về tổn thất phúc lợi do thiệt hại môi trường dọc theo bờ biển Alaska gây ra bởi sự cố tràn dầu của tàu Exxon Valdez năm 1989. Nghiên cứu này là một minh chứng nữa cho khả năng xuất sắc của McFadden trong việc kết hợp nhuần nhuyễn lý thuyết kinh tế với phương pháp kinh tế lượng trong các nghiên cứu thực nghiệm về những vấn đề xã hội quan trọng.
Tài liệu tham khảo và tài liệu đọc thêm
- https://www.nobelprize.org/prizes/economic-sciences/2000/popular-information/
- https://www.nobelprize.org/prizes/economic-sciences/2000/advanced-information/
- Amemiya T. (1987), Discrete Choice Analysis, in P. Newman, M. Milgate and J. Eatwell (eds.), The New Palgrave – A Dictionary of Economics, Macmillan.
- Heckman J.J. (1987), Selection Bias and Self-Selection, in P. Newman, M. Milgate and J. Eatwell (eds.), The New Palgrave – A Dictionary of Economics, Macmillan.
- Heckman J. J. and J. Smith (1995), Assessing the Case for Social Experiments, Journal of Economic Perspectives 9, 85-110.
- Maddala, G. S. (1983), Limited-Dependent and Qualitative Variables in Econometrics, Cambridge University Press.
- McFadden D. L. (2000), Disaggregate Travel Demand’s RUM Side: A 30-Year Retrospective (pdf), manuscript, Department of Economics, University of California, Berkeley.
- Small, K. A. (1992), Urban Transportation Economics, Fundamentals of Pure and Applied Economics, Harwood Academic Publishers.